Exploitable Antipatterns in Unicode Normalization
date
Sep 17, 2019
slug
exploit-in-unicode-normalization
status
Published
tags
安全研究
summary
这一篇文章源自于Black hat 2019的一个议题,有一个详细的ppt
看着好像挺有趣,拿过来学习一下,而且最近也有CTF题目出现了有关这个的知识点,结合一下这个题目看看,主要是复习机试没兴趣,得找点其他东西
看看。
type
Post
这一篇文章源自于Black hat 2019的一个议题,有一个详细的ppt看着好像挺有趣,拿过来学习一下,而且最近也有CTF题目出现了有关这个的知识点,结合一下这个题目看看,主要是复习机试没兴趣,得找点其他东西看看。
背景
从这个议题来看应该是个编码问题导致的漏洞
议题人给出了𓀬.net这样的一个网址,但是会跳转到
http://xn--fq7d.net/,这是一个人站在两头长颈鹿上,是一个埃及的文字代表忙碌。为什么会出现这种情况?需要了解这是怎么编码解码的~一些基础
什么是IDN?
国际化域名IDNs (Internationalized Domain Names)也称多语种域名,是指非英语国家为推广本国语言的域名系统的一个总称,例如含有日文的为日文域名,含有中文的域名为中文域名。简单滴说就是非英语表示的域名。
Punycode
是一种表示Unicode码和ASCII码的有限的字符集。例如:“münchen”(德国慕尼黑)会被编码为“mnchen-3ya”。用于DNS系统的编码 ,防止所谓的IDN欺骗。
在IDNs(国际化域名Internationalized Domain Names)推出以后,为了保证兼容以前的DNS,所以,对这些非英语的字符进行punycode转码,转码后的punycode就由26个字母+10个数字,还有“-”组成。
IDN的执行过程

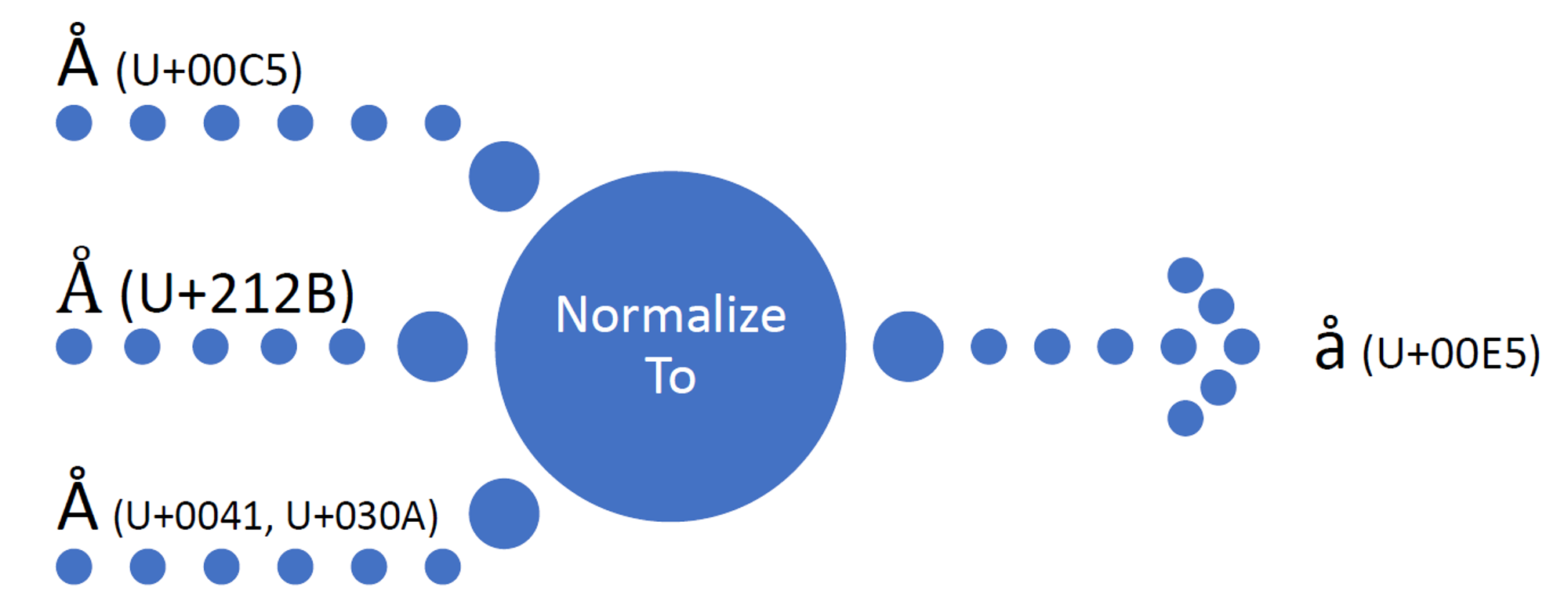
一共是两个步骤,第一个是Normalization,普通化,此时,就是把各国的文字变成一个标准的形式,类似一个过渡
第二个就是一个punycode转码,将unicode转化成acsii
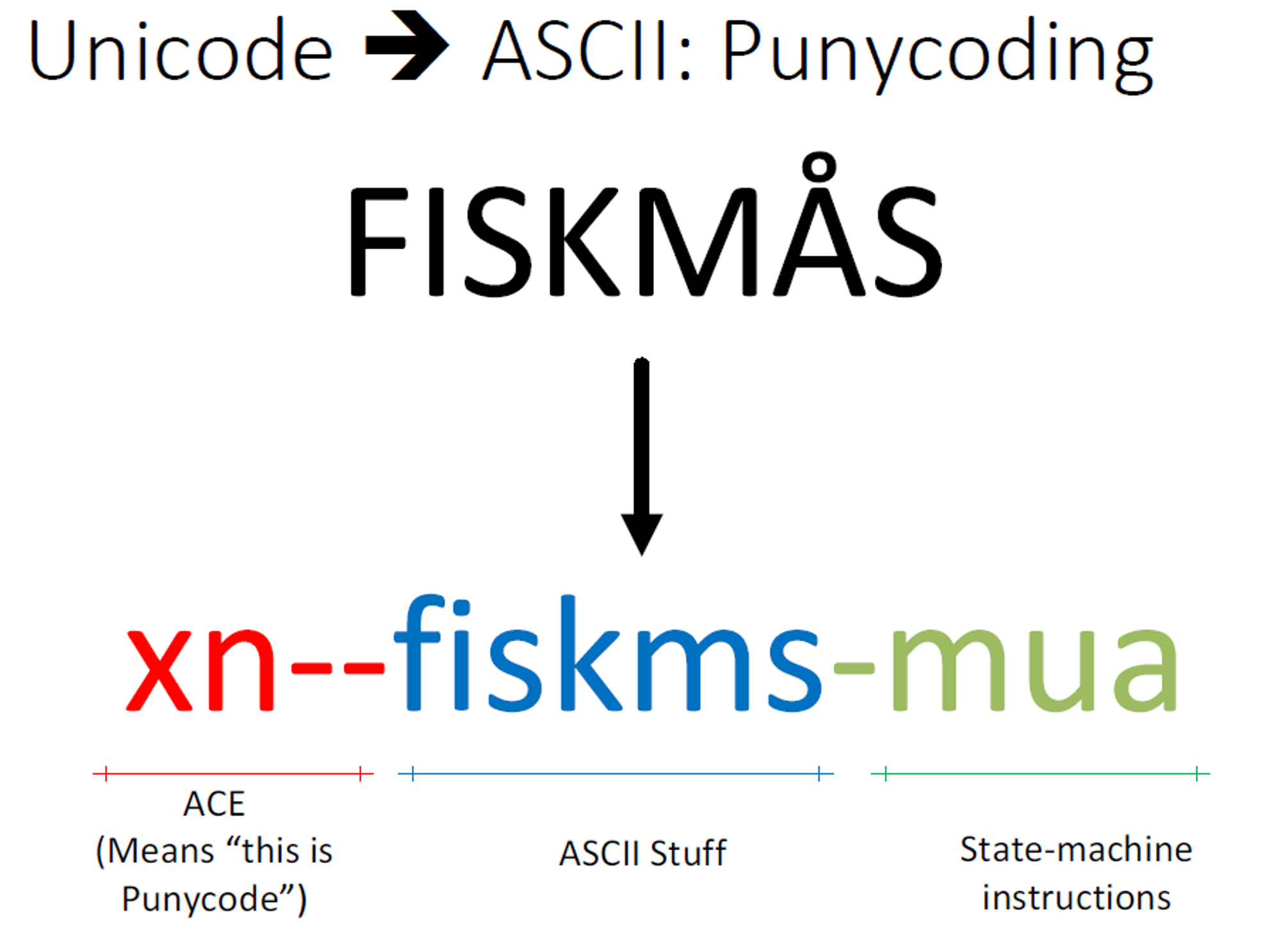
这个议题指出关键点在于部分字符在经过Normalization这一部分的时候直接变成ascii码,然后如果在经历一遍punycode转码也是没啥不同,还是ascii码,就是下图,可以使用该网址进行测试
https://www.punycoder.com/:

这样的问题可以利用在很多跳转漏洞上,该议题的作者在ppt上也指出他在一些浏览器和在哪些编程语言中发现的相似漏洞点

当然很多CVE也已经被修复了,可能是因为我没更新python,我自己的python还是存在这个问题的(⊙o⊙)…
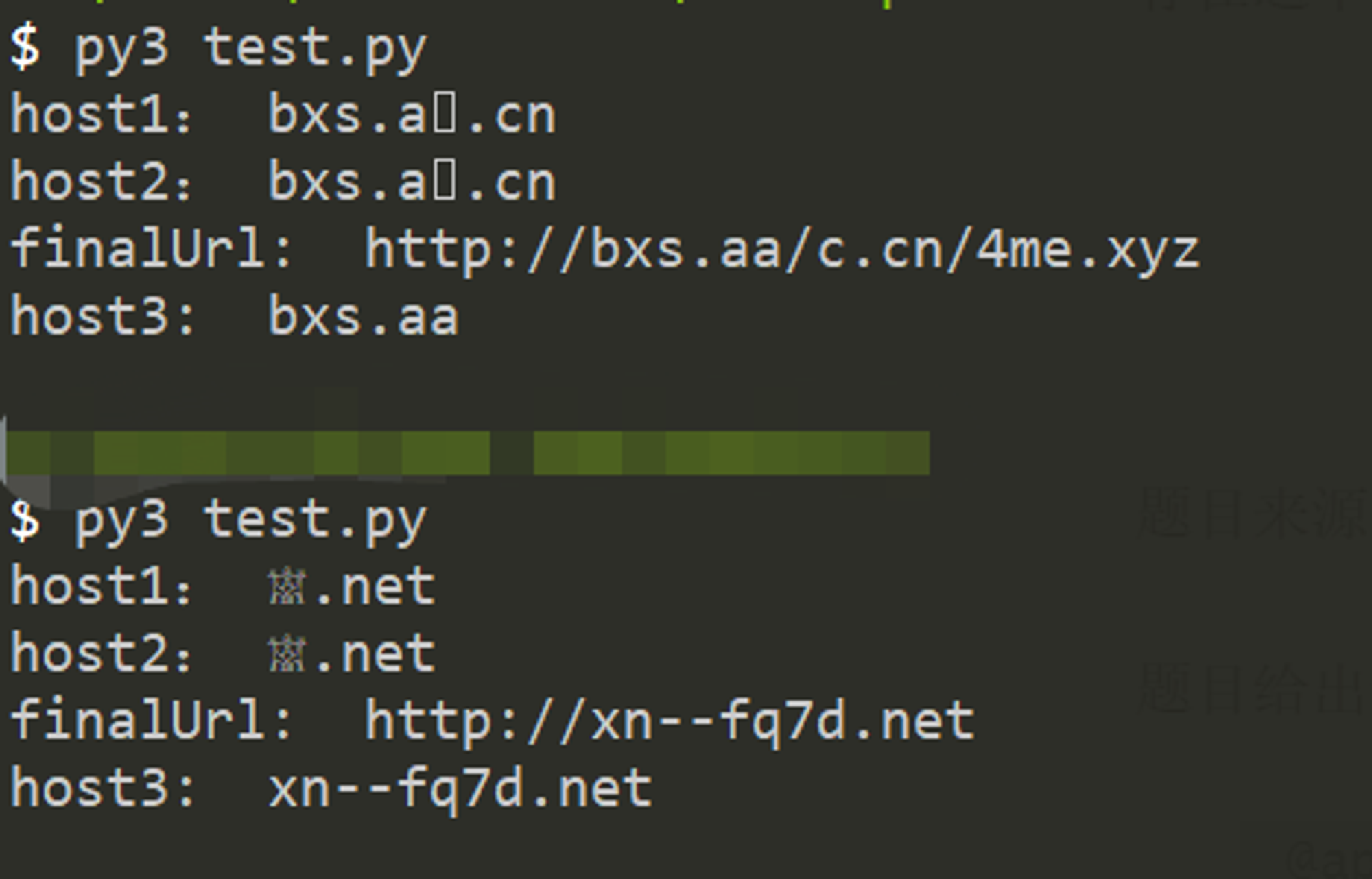
当然也不止上面那一个字符存在这样的问题,借用altman大佬的fuzz脚本,可以把其他类似字符也搞出来,原理很简单就是,从ASCII以外的字符去判断,以是否存在
-关键字作为判断条件即可,我就不重复造轮子了。。for iin range(128,65537):
tmp=chr(i)
try:
res = tmp.encode('idna').decode('utf-8')
if("-")in res:
continue
print("U:{} A:{} ascii:{} ".format(tmp,res,i))
except:
pass下面就结合题目学习一下了233333
题目给出部分源代码:
@app.route('/getUrl', methods=['GET', 'POST'])
def getUrl():
url = request.args.get("url")
host = parse.urlparse(url).hostname
if host == 'suctf.cc':
return "我扌 your problem? 111"
parts = list(urlsplit(url))
host = parts[1]
if host == 'suctf.cc':
return "我扌 your problem? 222 " + host
newhost = []
for h in host.split('.'):
newhost.append(h.encode('idna').decode('utf-8'))
parts[1] = '.'.join(newhost)
#去掉 url 中的空格
finalUrl = urlunsplit(parts).split(' ')[0]
host = parse.urlparse(finalUrl).hostname
if host == 'suctf.cc':
return urllib.request.urlopen(finalUrl).read()
else:
return "我扌 your problem? 333"
</code>
<!-- Dont worry about the suctf.cc. Go on! -->
<!-- Do you know the nginx? -->
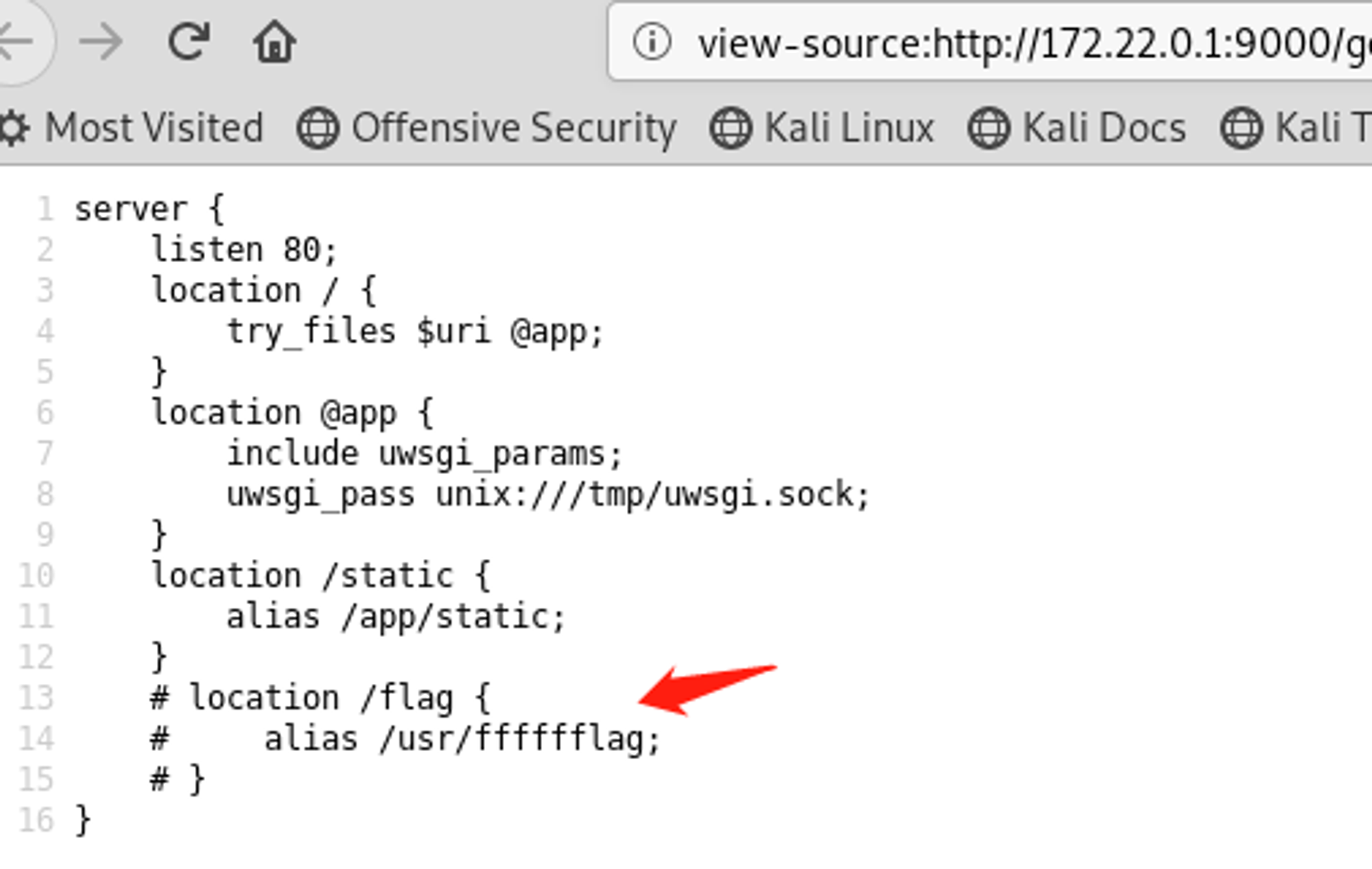
反正这个代码的意思就是域名里面不允许出现
suctf.cc,但最后经过Normalization处理之后满足suctf.cc就可以读取文件了,正好是上面的知识点,我们只要找到一个字符代替其中的一个字符即可,这里从fuzz的字符中找到C去替代,最后使用file协议去读取文件,先是按照提示读取nginx的配置文件,file://suctf.cC/../../../../usr/local/nginx/conf/nginx.conf,然后再去读取flag就好